Introduction
CPython is the most common implementation of Python used extensively by millions of developers worldwide. However, achieving true parallelism in CPython process has always been a tough nut to crack. Here, we’ll try to better understand parallelism, concurrency, in the context of operating systems & Python. Finally, equipped with all of this knowledge and new Python language internals, we’ll look at a possible mechanism of achieving true parallelism for pure Python code running in a single CPython 3.12 process.
If these concepts sound alien to you, don’t worry, we’ll cover it all in the context section. You can re-read the introduction after going through it.
If you’re here to just play around with true parallelism in Python, please use this link.
Context
Let’s first briefly cover few topics that will come handy in our discussions. Feel free to skip certain sections as per your knowledge level.
Concurrency & Parallelism
- Parallelism: When tasks literally run at the same time (e.g. creating next frame to display for a video game uses multiple GPU & CPU cores working on math problems at the same)
- Concurrency: When one or more tasks run in overlapping time periods, but not necessarily at the same instant. This is ideal for tasks waiting for I/O where only one of the different tasks might be running on a processor at a time. (e.g. while waiting for a network call, a web-browser can keep reading user inputs)
Concurrency & parallelism in operating systems
Let’s cover basic parallelism/concurrency primitives in modern operating systems:-
- Process: A process is execution of a program which includes all the program code, data members, resources, etc. Different processes are independent, and memory, resources, etc. are typically not shared.
- Thread: An entity within a process that can be scheduled for execution. Different threads of a process typically share memory among themselves, however, they can have different execution stacks.
Here, by default, in most modern operating systems, different threads of a process can run on different processors (i.e. literally at the same time). Since multiple threads can run at the same time, we need to be a bit more careful when sharing objects across multiple threads. We need to ensure that only one thread can write to a shared object at one point using “locks” to prevent memory corruption. Here, whenever a process/thread tries to acquire a lock held by another thread/process, it has to wait for the other thread/process to relinquish the lock. This is known as lock contention, which acts as a bottleneck in most parallel systems.
Another point worth noting is that not all threads/processes can always run on a processor at any given time. Hence, for threads and processes, the operating system generally orchestrates which tasks to run on the available processors at a given time. Here, the OS has to ensure that each of the threads recieve some CPU time, to ensure none of them get “starved” i.e. stuck in waiting state. Due to this, processors have to constantly switch from one thread/process to another, leading to a “context switch” overhead. We should aim to generally avoid this “context-switch” overhead as much as possible. Also, in this article, any task that is waiting on a user/network I/O are referred to as “I/O-bound tasks” whereas any task that requires CPU (e.g. mathematical operations) to proceed further are called “CPU-bound tasks”.
Python & multi-tasking
Here, for the purposes of this blog, Python=CPython, as it is the most widely used distribution of Python. In Python, we can achieve concurrency by using threads & coroutines (outside the scope of this post). However, despite Python internally using simple OS threads for multi-threading, Python code can’t actually run parallely.
Why can’t Python code run parallely?
Python language developers decided against allowing parallelism for Python code running in CPython to keep its implementation simpler (memory allocation, garbage collection, reference counting, etc. is much simplified). This also makes single-threaded performance faster, as CPython doesn’t have to worry about synchronizing various threads.
How does Python prevent parallelism?
Python prevents parallelism by introducing the concept of a GIL (Global Interpreter Lock). This lock needs to be acquired before any code runs in Python interpreter. Since each line of Python code runs in Python interpreter (Python being an interpreted language), so, this essentially forbids parallel execution of Python threads in most cases, as only one thread can have the GIL acquired at a given time.
If only one thread can have GIL at a time, then, how are Python threads concurrent?
Python has internally implemented a “context-switch” paradigm similar to operating systems, which releases the Global Interpreter Lock (GIL) and allows other threads to run their operations once either of the following events occur:-
- I/O request: When a thread executing Python code makes an I/O request, it internally releases the GIL & attempts to re-acquire it only after the I/O operation is complete.
- 100 “ticks” of a CPU-bound Python thread: When a thread running Python code completes roughly 100 Python interpreter instructions, it attempts to release GIL to ensure other threads do not get “starved”.
Hence, multiple I/O requests can run in parallel in Python. However, for CPU-bound tasks executing in Python, using multiple threads doesn’t provide any advantages.
Python & parallelism
The simplest way to achieve parallelism in Python is using multiprocessing module, which spawns multiple separate Python processes, with some sort of inter-process communication to the parent process. Since spawning a process has some overhead (and isn’t very interesting), so, for the purpose of this article, we’ll limit our discussion to what we can achieve using a single Python process.
A process running Python code can still have pieces of non-Python code, which can run parallelly without the limtations imposed by the GIL. However, CPU-bound Python code needs a Python interpreter, and must wait for GIL to execute.
Hence, libraries like Numpy internally use C/C++ for computations, getting rid of the interpreter overhead. This also allows for parallelism by relinquishing GIL when running non-Python code and allowing for truly parallel threads. Refer: Numpy multithreaded parallelism by Superfastpython.com.
Running truly parallel CPU-bound code using C/C++ extensions
We can write Python modules in C/C++ by following the following documentation: Extending and Embedding the Python Interpreter.
Here, we can internally relinuqish GIL as part of our hand-written C/C++ functions allowing the C++ code to be run parallely from multiple threads without any GIL limitations.
Example:
PyObject* py_function(PyObject* self, PyObject* args) {
auto c_args = /** Code to convert PyObject* args to C++ args */;
// Release GIL
Py_BEGIN_ALLOW_THREADS
// Run pure C++ code
auto c_ret = c_function(c_args);
// Re-acquire GIL
Py_END_ALLOW_THREADS
return /** Code to convert c_ret to PyObject* */;
}
The above pattern is commonly used by C/C++ extensions for Python allowing multiple threads to run in parallel. Moreover, these C/C++ functions can internally spawn multiple threads as well to achieve even better performance. Note that since the C++ code gets compiled to machine code as part of building the C++ extension, hence the C++ extension also provides much faster performance than running this code in Python interpreter even without putting parallelism into the equation.
However, this method is only suited for running non-Python code (e.g. C/C++) parallely.
I have written a basic Python function using C++ extensions, which performs an expensive mathematical task after relinquishing GIL through C++ functions, which can be seen below:
Running truly parallel CPU-bound code using sub-interpreters
With Python 3.12, Python internals underwent a major paradigm shift. Instead of having a single GIL per-process, support for multiple GILs in a single CPython process was added. This allows multiple Python code threads running in a single CPython process to run at the same time. For this, we can create multiple Python sub-interpreters, each having their own GIL. Refer PEP 0684.
Few things to note here:-
- Multiple Python interpreters in a single process, as a concept, existed long before Python 3.12. However, each interpreter created in a single process shared a single GIL. Thus, only one of the sub-interpreters ran at any given instant in a CPython process before Python 3.12. Hence, this concept of multiple interpreters was mainly used to achieve ‘isolation’ (outside the scope of this article), and not seen as a way to boost performance.
- Currently, there is no way to directly interact with these APIs from Python code as of CPython 3.12.
Why sub-interpreters?
- Cheaper than spawning processes, pricier than threads.
- No need for acquiring GIL while evaluating Python code, hence, no lock contention associated with acquiring GIL.
- Expected to be standardized by Python 3.13 with a proper communication channel between multiple interpreters. Refer PEP 0554 for more details.
Implementation of parallelism using sub-interpreters
To play around with sub-interpreters, I hacked together a module, subinterpreter_parallelism to achieve parallelism of arbitrary Python code by using sub-interpreters.
Since sub-interpreters aren’t a part of the stdlib as of Python 3.12, this module was implemented using a C++ extension module, and can be seen below:
Usage
from subinterpreter_parallelism import parallel
# Run 3 threads of pure python functions in parallel using sub-interpreters.
result = parallel(['module1', 'func1', (arg11, arg12, arg13),)],
['module2', 'func2', (arg21, arg22)],
['module3', 'func3', tuple()])
Using this setup, I was able to achieve almost full utilization of all processing cores of my CPU (i.e. 1995% CPU usage on a system with nproc=20 and 20 Python functions running in parallel), demonstrating true parallelism. Moreover, the performance using this setup was faster than using multiprocessing module.
Design
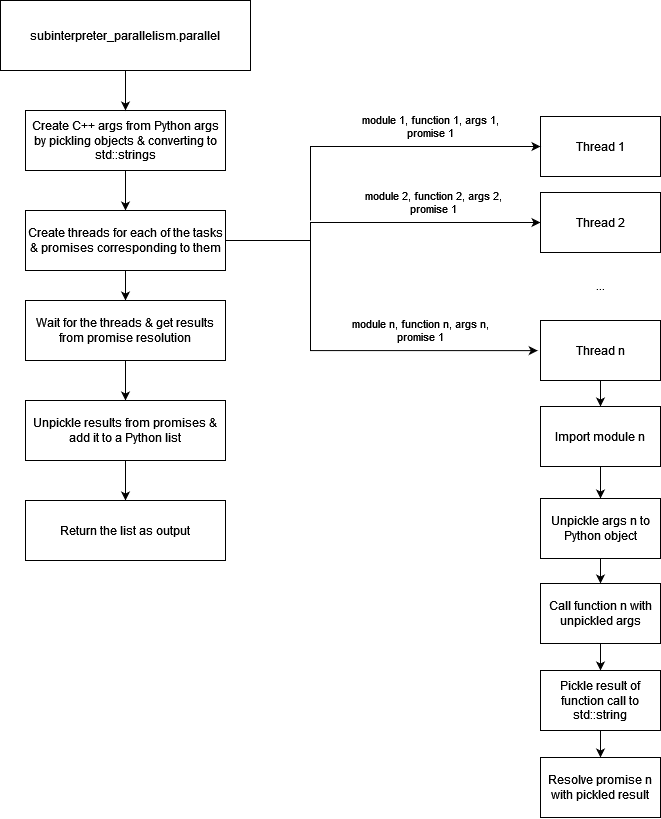 |
|---|
Flowchart of subinterpreter_parallelism module |
Sub-interpreters aren’t all roses and sunshine
- This might not work well, or at all, with various other commonly used Python libraries (e.g. Numpy) in its current state. This is because, by default, all C/C++ extension modules are initialized without support for multiple interpreters. This holds true for all modules created using Cythonize (like Numpy), as of April, 2024. This is because C extension libraries interact regularly with low-level APIs (like
PyGIL_*) which are known to not work well with multiple sub-interpreters. Refer caveats section from Python documentation. Hopefully, more libraries add support for this paradigm as it gains more adoption. - Performance should still be much better with pure C/C++ code for highly CPU bound tasks, due to the overhead associated with Python being an interpreted language.
- Since very little is shared between interpreters in my hacked together module, things like logging configuration, imports etc. need to be explicitly provided in the functions being run parallely.
At the end of the day, this is just an experimental project to test things out.
Benchmarking setup
Here, I’ve used the following Python code for benchmarking:-
for i in range(n,1,-1):
k *= i
k %= 1000000007
Similarly, I’ve implemented the same logic in C++ as well to benchmark pure C++ extension variant:-
for (i = val; i >= 1; --i) {
s *= i;
s %= 1000000007;
}
With these pieces of code in place, I benchmarked all the different paradigms for parallelism discussed here with random inputs. For more details on the benchmarking and to replicate it locally, refer the usage step of github.com/RishiRaj22/PythonParallelism.
Performance numbers
| Method | Total time taken |
|---|---|
| Multi-processing (1 process per Python task) | 15.07s |
| Multi-threading with sub-interpreters (1 thread per Python task) | 11.48s |
| Multi-threading for C++ extension with GIL relinquished (1 thread per C++ task) | 0.74s |
Conclusion
- Sub-interpreters seem like a promising mechanism for parallel Python code with significant advantages (>20% performance improvement over multiprocessing in the above mentioned simplistic benchmark), etc.
- Sub-interpreters, though good for parallelizing pure Python code, are not compatible out of the box with C/C++ extension based libraries like Numpy. Refer the 1st point mentioned above for more details. We’re yet to understand if this paradigm of programming will be widely supported in the Python ecosystem.
- If performance is a big concern, relying on C/C++ extension functions still seems more suitable due to the speedup gained from compiled code.
- With Python 3.13, sub-interpreters will become much more appealing and the code written here should be turned redundant as interpreters would be made part of the stdlib itself. However, it’s still fascinating to see how we can achieve similar results in Python 3.12.
- If you’re more interested in learning about sub-interpreters for parallelism, you can read Anthony Shaw’s blog.
Source code
The entire source code discussed here, along with benchmarking code & instructions to build & use the code can be found at github.com/RishiRaj22/PythonParallelism.